大数据时代,Hadoop是热门的Apache开源项目,公司大多基于其商业化从而满足自身的数据作业需求。CDH(Cloudera’s Distribution, including Apache Hadoop),是Hadoop众多分支中的一种,由Cloudera维护,整合Hadoop及一系列数据服务,关于CDH,官网给予的解释如下:
Critical Capabilities for Data Warehouse Database Management Systems
官网提供安装包、部署手册以及API说明
安装过程参考: http://blog.csdn.net/jdplus/article/details/45920733 http://blog.csdn.net/a921122/article/details/51939692 基于其上,进行适当的修改和完善
需要在所有的节点上执行,因为涉及到的端口太多了,临时关闭防火墙是为了安装起来更方便,安装完毕后可以根据需要设置防火墙策略,保证集群安全。
CentOS 7.x 关闭防火墙命令(早期版本为iptables,大家自行查找) # systemctl stop firewalld.service #关闭防火墙 # systemctl disable firewalld.service #关闭开机自动启动集群中所有主机必须保持时间同步,如果时间相差较大会引起问题
具体实现:master节点作为ntp服务器与外界对时中心同步时间,随后对所有datanode节点提供时间同步服务。 所有datanode节点以master节点为基础同步时间。 所有节点安装相关ntp组件 # yum install ntp 启动ntp,及设置开机启动 # service ntpd start # chkconfig ntpd on note: 本文目前只启动Master节点,下述的ntp同步组从配置未测试,网上提示的配置如下: 主节点配置 # vi /etc/ntp.conf driftfile /var/lib/ntp/drift # Permit time synchronization with our time source, but do not # permit the source to query or modify the service on this system. restrict default kod nomodify notrap nopeer noquery restrict -6 default kod nomodify notrap nopeer noquery # Permit all access over the loopback interface. This could # be tightened as well, but to do so would effect some of # the administrative functions. restrict 127.0.0.1 restrict -6 ::1 # Hosts on local network are less restricted. restrict 192.168.39.31 mask 255.255.255.0 nomodify notrap # Use public servers from the pool.ntp.org project. # Please consider joining the pool (http://www.pool.ntp.org/join.html). server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst 配置文件修改完毕后,通过# service ntpd restart重启ntp服务。检查是否成功,用ntpstat命令查看同步状态,出现以下状态代表启动成功: synchronisedto NTP server () at stratum 2time correct towithin74 mspolling server every 128 s 如果出现异常请等待几分钟,一般等待5-10分钟才能同步。 在其他节点,直接运行 # ntpdate -u masterCloudera Manager Server和Agent都启动以后,就可以进行CDH5的安装配置。 打开浏览器,访问master:7180/cmf/login 由于CM Server的启动需要花点时间,这里可能要等待一会才能访问成果,可能需要3-5分钟,默认的用户名和密码均为admin: check:本机可以先curl -i master:7180/cmf/login测试,有返回结果后,在浏览器端,输入ip:7180/cmf/login进行配置:
note: 此处注意,若本机可curl连接上,但其他主机连接不上,考虑:主机防火墙是否正常关闭;两台主机是否在同一个局域网
pic1 . 进入页
pic2. CDH版本(CDH Express免费, Enterprise收费)
note:以下图借用CM 5.7安装图
当各Agent节点正常启动后,可以在当前管理的主机列表中看到对应的节点。选择要安装的节点,点继续。 下一步,出现parcel自检测包名,如果本地Parcel包配置无误,选目标版本(例如CM5.7.1),直接点继续就可以了(若没有出现对应版本,则重启CM server和agent)。
pic3. parcel包版本检测
继续,如果配置本地Parcel包无误,那么下图中的已下载,应该是瞬间就完成了,然后就是耐心等待分配过程就行了,这个过程的速度就取决于节点之间的传输速度。
当前受管:假如在安装的时候出现问题,如网络连接中断,机器死机,继续安装的时候可能会出现查询不到机器,并且根据ip搜索机器的时候,出现“当前受管”的状态为“是”,安装失败的机器不能再选择了。
至此,所有节点部署完成
下一步主机检查,遇到以下问题: Cloudera 建议将 /proc/sys/vm/swappiness 设置为 10。当前设置为 60。使用 sysctl 命令在运行时更改该设置并编辑 /etc/sysctl.conf 以在重启后保存该设置。
# echo 10 > /proc/sys/vm/swappiness 第二个警告,提示执行命令: # echo never > /sys/kernel/mm/transparent_hugepage/defrag执行完毕,重启后,警告依然,暂时不处理
继续之后,进入到安装服务页面
note:从这里开始,所有的服务,既可以通过下述自助来安装一系列服务;也可以手动在CM管理页面一个一个添加
之前安装时选择一次性安装一系列服务,由于没有新建hue数据库导致hue服务安装不上,所以后面选择一个一个安装,在前期搭建环境时这样更好,起码出现问题可以锁定是哪个服务。
点击页面上Cloudera MANAGER,回到主节点页面
出现cluster1群集1,点击下拉,选择“添加服务”
HDFS,HIVE, HUE,Oozie, YARN, ZOOKEEPER是核心Hadoop的几个服务,分别安装,由于这些节点存在依赖关系,需注意先后顺序(当然,安装时CM会警告),顺序是: Zookeeper, hdfs, yarn, hive, oozie, hue
注意:在安装hive, hue和oozie时,要将mysql驱动jar拷贝到相应位置
# cp /opt/cm-5.9/share/cmf/lib/mysql-connector-java-*-bin.jar /opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hive/lib/ # cp /opt/cm-5.9/share/cmf/lib/mysql-connector-java-*-bin.jar /opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23 /lib/hue/lib/ # cp /opt/cm-5.9 /share/cmf/lib/mysql-connector-java-*-bin.jar /var/lib/oozie/ 按需安装完服务后,可在集群界面(即Cloudera MANAGER)看一下集群的状况 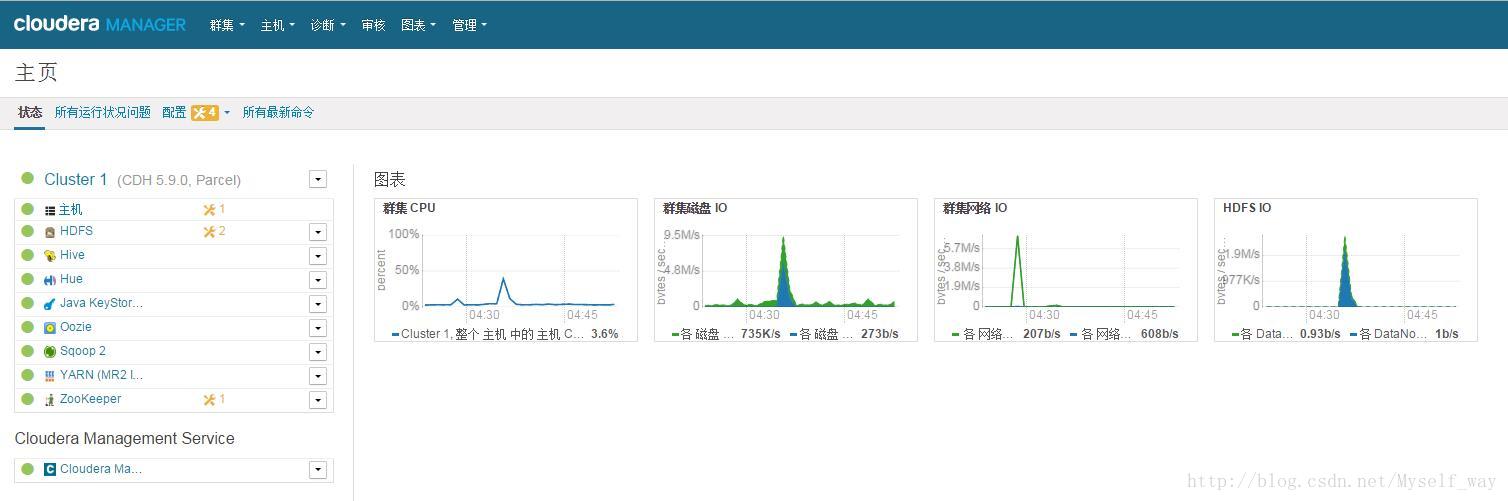 绿色:良好黄色:运行不良红色:存在问题CM虽然配置麻烦,但日志齐全,每个操作,都能找到相应的运行日志,日志对于配合、调试和查看任务进度都有很大的帮助
群集日志入口为
各服务节点也有日志入口,支持日志筛选 分为stdout(所有日志), stderr(错误日志), 在细节上支持分级别(INFO, TRACE, DEBUG等)筛选
在部署完成以后,会出现大量问题,其中有大量警告,是由于var/log/*的权限问题造成的。 在master上,运行chmod -R 777对应的文件夹修改权限即可。
出现oozie和hive不能成功启动 一般是因为缺少jdbc,复制到相应位置即可,位置请。或者是由于mysql数据库中的表造成的,可能是表已经存在了
service monitor和host monitor都无法启动 一般也是由于var/log/*的权限问题造成的
service monitor和host monitor正常启动,但是无法获取到图表数据 注销admin重新进入,或者等一下
hdfs不能正常启动 可能是因为/dfs的权限原因,提高/目录的权限
hdfs和yarn的端口不再是9000和10020,默认的是8020和8021
如果使用Windows远程调试,请保证host文件(C:/Windows/System32/drivers/hosts)和集群上的host文件内容一致。
主机崩溃怎么办? 一般来说崩溃了,直接重启就好。不过一定记得要再次启动cm的agent和server服务
通过CM启动Hive报错 org.apache.hadoop.hive. metastore.HiveMetaException: Failed to load driver 这种情况,是缺少jdbc驱动,添加jdbc驱动到相应的lib下面。hive的lib路径是/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hive/lib
放置好lib之后,启动hive,接着出现java.sql.SQLException:Column name pattern can not be NULL or empty. 原因是,一开始使用的jdbc lib是6.x的最新版本,但5.x和6.x在连接时针对某些默认值的检测值不同,将CM内用到的所有jdbc lib修改为5.x之后解决了这个错误
启动hdfs后,报警:群集中有704个副本不足的块,百分比副本不足的块:100%。临界阈值:40% 解决方案:通过命令更改已经上传的文件的副本数(使用hdfs用户)
# su hdfs hadoop fs -setrep -R 2 / 利用HUE执行max , count, or any complex query, 任务accepted了,但是maps或者reduces进度都是0 (Hadoop yarn job is getting stucked at map 0% and reduce 0%) 对每个工作节点都应该设置足够的内存用于job,可配置的是 NOTE:可通过直接vim编辑相应xml,增加或修改配置。另外,这些配置在CM页面上有对应的UI(每个服务节点都有独立的配置UI,存储分配在“类别 -> 资源管理”,图形界面操作后,变化会体现在xml中,重启CM及根据各个提示重启各节点服务就可。 0x01. yarn-site.xml (UI操作:YARN -> 资源管理) <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2200</value> #备注:扩大以M为单位 <description>Amount of physical memory, in MB, that can be allocated for containers.</description> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>500</value> #扩大 </property> 已测试在16G内存机器上,一个可行的配置是: yarn.app.mapreduce.am.resource.mb 1Gyarn.nodemanager.resource.memory-mb 8Gyarn.scheduler.minimum-allocation-mb 1G0x02. mapred-site.xml (可选,若0x01生效,此步不必修改。UI操作:Gateway -> 资源管理)
<property> <name>mapreduce.map.memory.mb</name> <value>256</value> #扩大 </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>256</value> #扩大 </property> <property> <name>yarn.app.mapreduce.am.resource.mb</name> <value>400</value> #扩大 <source>mapred-site.xml</source> 公司一个可行的配置是: mapreduce.map.memory.mb 1Gmapreduce.reduce.memory.mb 1Gyarn.app.mapreduce.am.resource.mb 1G13.python连接hive时, Could not start SASL: Error in sasl_client_start (-4) SASL(-4): no mechanism available: no 安装3个库
cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapiHello, Hadoop ! ! !